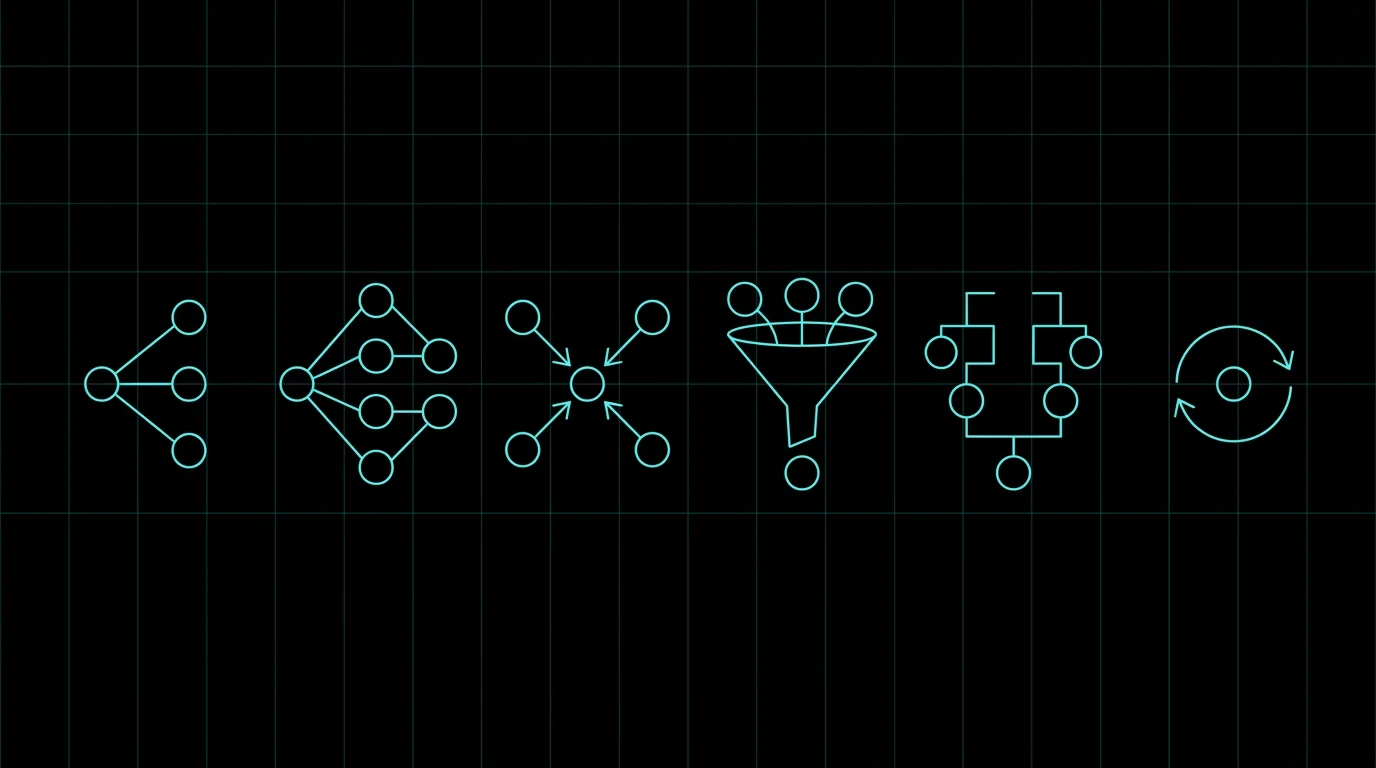
If you build with AI agents, you have probably seen some version of the diagram: a handful of named workflow patterns, each a different way to wire models, tools, and steps together. The patterns are genuinely useful. Most production agents are a combination of five or six of them, and knowing which one fits a job saves a lot of wasted orchestration.
This guide walks through the six patterns and where each one earns its place. Then it spends most of its time on the one pattern that behaves differently from the rest. Verification looks like just another box to wire up, so teams build it the obvious way and ship it. The research says the obvious way is the way that does not work. The fix is small, specific, and worth getting right before you trust an agent to check anything.
What's the difference between a workflow and an autonomous agent?
Worth settling first, because the patterns below sit on one side of this line. In Anthropic's framing, a workflow is a system where models and tools run through paths you defined in advance. An autonomous agent is a system where the model decides its own steps and tool calls at runtime.
The distinction matters for reliability. A workflow is predictable because you drew the graph. An autonomous agent is flexible because it draws its own, which also means it can wander, loop, or commit to a wrong plan with full confidence. Most teams reach for autonomy too early. The patterns below are workflow patterns precisely because predefined structure is where reliability lives.
Read the six as a vocabulary, not a hierarchy. None is more advanced than another. Each answers a different question about how work should move through your system, and a real agent usually stitches several together.
The six AI agent workflow patterns at a glance
Here are the six, with the plain-language name, the canonical name you'll see in the literature, and the one question each answers. The deeper treatment comes after.
1. Classify-And-Act
A classifier reads the task and sends it down one of several branches. Canonical name: routing. Answers: which handler should take this? Use it when inputs fall into distinct categories that each deserve different handling.
2. Fanout-And-Synthesize
Split a task across several workers running at once, then combine their output. Canonical name: parallelization, by sectioning or by voting. Answers: how do I cover breadth fast, or get more than one read on the same thing?
3. Adversarial Verification
A worker produces something; separate verifiers check it. Canonical name: the evaluator side of evaluator-optimizer. Answers: is this output actually correct? This is the pattern most of this guide is about, because it is the one most often built in a way that cannot do its job.
4. Generate-And-Filter
Several generators propose candidates; a rubric or dedupe step keeps the best and discards the rest. Answers: how do I get a good option when the solution space is wide? Use it for ideation, naming, design variants, or any task with many plausible answers.
5. Tournament
Candidates compete in pairwise judgments until one wins. Answers: which of these is best when I can compare two at a time more reliably than I can score all at once? Use it for ranking, evals, and taste calls against a rubric.
6. Loop Until Done
An agent runs, asks whether there is more to find, and spawns another pass until the answer is no. Canonical name: the optimizer loop, or autonomous closed-loop. Answers: how do I handle a job whose size I don't know up front? Use it for discovery work like audits, research sweeps, and migrations.
Where each pattern shines
The patterns map cleanly onto the kinds of work people actually point agents at. One useful way to choose: start from the job, not the pattern.
| Use case | The shape | Pattern |
|---|---|---|
| Migrations | One agent per fix, run in parallel. | Fanout-And-Synthesize |
| Research | Gather broadly, then verify and cite before you trust it. | Fanout + Adversarial Verification |
| Verification | One agent per claim, each checking independently. | Adversarial Verification |
| Sorting / ranking | Rank a large set by comparing pairs. | Tournament |
| Triage / routing | Classify the input, send it to the right handler. | Classify-And-Act |
| Root cause | Generate competing theories, filter to the supported one. | Generate-And-Filter |
Notice that verification shows up twice: once as its own job, and once as the quality gate inside research. That is the tell. Verification is not only a pattern you choose, it is a step almost every other pattern eventually needs. Which is exactly why building it correctly matters more than building any single one of the others.
The five routine patterns, briefly
Five of the six are well understood and rarely controversial. Quick notes on each, then the one that deserves real scrutiny.
Classify-And-Act (routing)
Cheap, fast, and reliable when your categories are clean. The failure mode is a vague classifier that sends edge cases down the wrong branch, so keep the categories few and distinct, and give the classifier an explicit fallback for inputs that fit none of them.
Fanout-And-Synthesize (parallelization)
Two flavors. Sectioning splits a task into independent parts that run at once. Voting runs the same task several times and aggregates. Voting feels like verification, and it is the trap this guide is about: running one model many times is not the same as asking several. More on that below.
Generate-And-Filter
Strong when the solution space is wide and judging is easier than generating. Spend your effort on the filter. A weak rubric keeps the wrong candidate, and a good generator with a sloppy filter is just expensive noise.
Tournament
Pairwise comparison is more reliable than absolute scoring for many subjective calls, which is why it works well for ranking and evals. The cost is more comparisons. Use it when getting the order right is worth the extra passes.
Loop Until Done
The right shape for unknown-size discovery. The discipline is the stopping rule: loop until a pass returns nothing new, not until a fixed count. The risk is a loop that never converges or one that quietly stops early and reports the job as finished.
The verification pattern everyone builds wrong
The other five patterns fail in ordinary ways. You can see a bad classifier or a runaway loop. Verification fails silently, and it fails because of how it is almost always built.
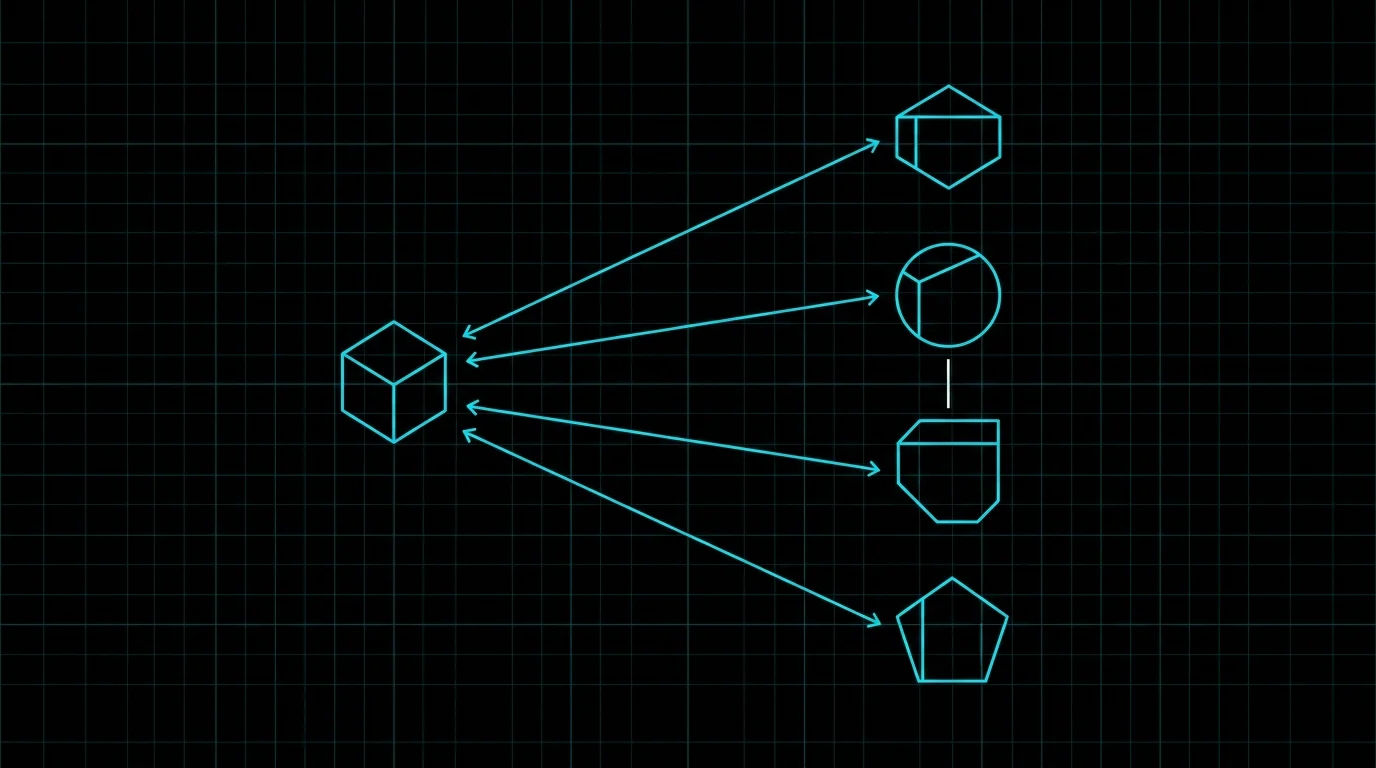
The way it usually gets built
You have an agent that produces something. You add a second step that checks it: a reflection pass where the model critiques its own draft, or an evaluator that scores the output and sends it back for revision. The evaluator is the same model, or another instance of the same model, sometimes with a 'be a harsh critic' instruction. It returns approved, the pipeline moves on, and the verification box is ticked.
Why that does not catch errors
Because the checker shares the blind spots of the thing it is checking. Two documented effects make a same-model verifier lean toward approval:
Self-preference
LLMs used as judges recognize their own writing and rate it more favorably. Panickssery and colleagues show that LLM evaluators recognize and favor their own generations, and that the strength of the self-preference tracks the model's ability to recognize itself. Follow-up work measuring self-preference bias in LLM-as-a-judge finds the same tilt. A model grading work that looks like its own is not a neutral referee.
Sycophancy
Models trained with human feedback drift toward telling you what you want to hear. Anthropic's study of sycophancy finds it across five frontier assistants and traces it to the training itself, not to any one prompt. Ask a model 'is this correct?' and the bias is toward yes, because agreement is what the training rewarded.
Put those together and a same-model verifier rubber-stamps. Worse, it rubber-stamps confidently, which reads as a clean verification when it is really correlated blindness. Near-unanimous approval from one model family is a warning sign, not a green light. This is the same reason one AI can't reliably fact-check another when both come from the same place, and it is rooted in the structural pull of sycophancy.
The fix is architectural, not a better prompt
A 'skeptic' persona on the same model is still the same model, drawing from the same probability distribution that produced the error. Adversarial in prompt is not adversarial in architecture. The verifier only earns its name when its errors are non-correlated with the generator's: a different vendor, a different training corpus, a different alignment regime. The diagram for pattern three shows several verifiers pointing back at one worker. The hidden requirement the diagram doesn't show is that those verifiers have to be genuinely different from the worker, and from each other.
This is the one place the obvious build and the correct build diverge. Same model checking same model gives you the feeling of verification with none of the catch rate. Different vendors checking the same claim is what TrueStandard runs: paste a draft, several models from different labs check the claims in parallel, and every disagreement is surfaced instead of smoothed over.
Why adding more verifier steps backfires
A natural reaction to an unreliable check is to add more checks. If one reflection pass is good, three should be better. Inside a single model family, that instinct makes things worse, not better.
Each step in an agent chain samples from the same distribution, so each step can introduce its own small error, and those errors compound rather than cancel. If a step is 95 percent reliable on its own, a twenty-step chain is not 95 percent reliable end to end. It is closer to a third, because reliability multiplies down the chain. That is a back-of-envelope illustration, not a published constant, but the direction is the point: adding same-family steps multiplies error, it does not catch it.
Anthropic names this directly in its guidance on building agents, warning about the compounding errors that come with longer autonomous chains. The deeper version of the math, and the April 2026 results behind it, are in our piece on why hallucinations are structural. The takeaway for pattern design is simple. Catching an error needs a signal that is not correlated with the one that produced it. More of the same model is correlated by definition.
What a verification pattern that actually catches errors looks like
Strip it down and a working verification step has three properties. None of them is exotic, and all three are easy to leave out.
Cross-vendor, not cross-prompt
The checkers come from different labs, so their errors don't line up with the generator's or with each other's. This is the property that does the actual work, and it is the one a single-model reflection loop can never have.
Generator separate from verifier
Whatever produced the output does not get a vote on whether it is correct. Self-preference makes a producer-as-judge tilt toward its own work, so the roles stay split.
Disagreement surfaced, not resolved away
When the checkers split, that split is the product, not a problem to hide. Agreement tells you confidence; disagreement tells you exactly which claim to look at. Near-unanimous agreement from one source gets treated as suspicious rather than final.
That is the shape behind the multi-model rather than multi-agent approach to verification. Multi-agent gives you many roles played by one model. Multi-model gives you many models, which is the only version that breaks the correlation. For checking facts, the second is the one that matters.
If you are wiring verification into your own agents, this is the bar: different vendors, separated roles, disagreement kept visible. It is also exactly what TrueStandard does as a finished layer, so you don't have to assemble and maintain the council yourself. Four frontier models from four labs check your draft and report where they disagree.
How to choose the right pattern
A short decision path. Start from the job and let it pick the pattern.
Do inputs fall into clean categories?
Classify-And-Act. Route each to its handler.
Do you need breadth or speed across independent subtasks?
Fanout-And-Synthesize. Split, run in parallel, combine.
Is the solution space wide and judging easier than generating?
Generate-And-Filter, or Tournament if you mainly need the best one ranked.
Is the job's size unknown up front?
Loop Until Done, with a stop-when-nothing-new rule.
Does the output's correctness actually matter?
Adversarial Verification, built cross-vendor with separated roles. For high-stakes factual claims, this is not optional, and it is the one you cannot fake with a single model.
Most real systems combine several of these. The combination is fine. The only one you cannot shortcut is the last.
Frequently Asked Questions
Can an AI agent verify its own output?
Not reliably. A model checking its own work shares the blind spots that produced the error, and two documented effects, self-preference and sycophancy, tilt it toward approving its own output. Reflection passes catch formatting and obvious mistakes; they do not catch confident factual errors, which are the ones that hurt.
What is the evaluator-optimizer pattern?
A loop where one component generates output and another evaluates it, sending feedback until the result passes. It works well when the evaluator is independent and the quality criteria are clear. It fails as a verification method when the evaluator is the same model as the generator, because then it is grading itself.
Is single-model or multi-model verification better?
Multi-model, for catching factual errors. The catch rate comes from non-correlated errors across different vendors. Running one model multiple times varies the wording but not the underlying distribution, so it does not add an independent check. Different labs do.
Isn't a reflection step enough to catch hallucinations?
Reflection improves structure and surface quality, and it helps on tasks where the model can check its work against a tool result, like running code. For free-form factual claims with no external signal, a same-model reflection step inherits the same uncertainty it is supposed to catch.
Which workflow pattern should I start with?
Start from the job. Clean categories point to routing; wide solution spaces point to generate-and-filter or tournaments; unknown-size discovery points to a loop. Whatever you build, if the output's correctness matters, add a cross-vendor verification step rather than trusting a single model to check itself.
Keep reading
AI Cloned Your Podcast. Now What?
Three different problems hurt real creators when AI is involved. Identity attestation, AI detection, and claim verification each need a different tool.
Can One AI Reliably Fact-Check Another AI?
If ChatGPT wrote the draft, can Claude safely verify it? Sometimes helpful, not sufficient by default — and the reason is what these models share, not what they don't.
What Is AI Slop, and How to Avoid It
Slop and AI-assisted work can look identical on the page. The line between them is whether you verified the output and can prove it.
Is There a Most Accurate AI Model?
The honest answer is no. The ranking changes with the task, the benchmark, and the month, and even the leader still hallucinates.
Why AI Is Confidently Wrong
Models sound certain every time, even when wrong. The confident tone you trust in people is worthless here. Here is the fix.
Verify Across Models, Not Within One
The verification pattern only works when the checkers come from different labs. TrueStandard runs your draft through four frontier models in parallel and surfaces every disagreement. Sixty seconds.
Start Verifying →